SKD 1s의 계산된 필드 8.2. 데이터 구성 시스템 표현 언어(1Cv8)
계산식 ACS 기능은 이해하기 다소 어려운 기능이며, 참조 정보에 적용한 예는 매우 부족합니다. 이 문서에서는 모든 개발자에게 유용할 것으로 예상되는 예제를 설명합니다.
- 그룹화의 누적 합계;
- 크로스탭의 누적 합계
- 이전 값을 얻는 단계;
- PM은 한 줄로 출력됩니다.
1. 발생주의 지표 획득
그룹화 수준에서 상품 수량을 누적 합계로 구해 보겠습니다. 이렇게 하려면 계산된 필드를 만듭니다(그림 1 참조)."리소스" 탭에서 계산된 필드에 대한 기능을 설정합니다.
CalculateExpression("Sum(QuantityTurnover)", "첫 번째", "현재")
첫 번째 레코드부터 현재 레코드까지 제품 수를 합산합니다(그림 2 참조).
항목의 누적 총 수량을 세부 기록 수준에서 얻어야 하는 경우 "계산된 필드" 탭에서 계산된 필드에 대해 CalculateExpression 함수를 설정합니다(그림 3 참조).
누적 합계를 얻는 수준에 따라 그룹화를 만듭니다(그림 4 참조): 리소스 수준 - 상품별 그룹화, 원격 제어 수준 - 세부 기록 그룹화.
 |
| 그림 4. 누적 합계가 포함된 보고서 그룹화 |
2. 이전 행에서 지표 값 가져오기
해당 날짜와 이전 날짜의 환율을 구해 보겠습니다. 이렇게 하려면 계산된 필드를 만들고 표현식 필드에 다음 표현식을 작성합니다(그림 5 참조).CalculateExpression("비율", "이전", "이전")
현재 행에 대한 이전 환율 값을 사용하는 함수의 마지막 매개변수는 데이터 수신을 제한합니다.
우리는 세부 기록 수준에서 작업하고 있으므로 즉시 "설정"탭으로 이동하여 세부 기록 그룹을 만듭니다.
3. 크로스탭에서 누적 합계로 지표 얻기
기간별로 발생 기준으로 상품 수량을 구해 보겠습니다. 이렇게 하려면 계산된 필드를 만듭니다(그림 1 참조). "리소스" 탭에서 계산된 필드에 대해 다음 표현식을 지정합니다(그림 6 참조).CalculateExpression("Sum(QuantityTurnover)", "기간", "첫 번째", "현재")
그룹화 수준에서는 각 항목의 기간에 따라 첫 번째 줄부터 현재 줄까지의 간격으로 상품 수량을 계산합니다.
"설정" 탭에서 행에 항목별로 그룹화하고 열에 기간별로 그룹화한 표를 만듭니다(그림 7 참조).
4. 한 줄에 표 형식의 데이터 출력
CalculateExpression 함수를 사용하는 방법을 포함하여 표 형식의 데이터를 한 줄에 표시하는 방법은 기사에서 설명합니다.1C에서 가장 편리하고 독특한 개발 도구 중 하나는 데이터 구성 시스템(DCS)입니다. 개발자가 코드를 작성하지 않고 보고서를 작성할 수 있는 정보 시스템은 거의 없습니다. 이 메커니즘은 보고 양식 개발을 단순화 및 가속화하고 사용자에게 출력 데이터 작업에 더 많은 기회를 제공하기 위해 개발되었습니다. 후자는 개발자의 작업을 기다리지 않고도 자신의 필요에 맞게 보고서를 독립적으로 사용자 정의할 수 있는 고급 사용자에게 매우 높은 평가를 받고 있습니다.
SKD를 통해 1C에서 보고서 만들기
ACS를 사용하여 보고서를 개발하는 프로세스는 다음 단계로 나눌 수 있습니다.
- 요청을 생성합니다. 편리한 인터페이스를 사용하여 수동으로 요청을 작성하거나 코드 없이 작성할 수 있습니다.
- 보고서를 설정합니다. 필드, 합계, 그룹화, 매개변수, 보고서 디자인을 선택합니다.
- 그런 다음 우리가 해야 할 일은 결과 보고서를 사용 가능한 방식으로 구성에 연결하는 것뿐입니다.
사용자가 액세스 제어 시스템에 대한 보고서를 사용자 정의할 수 있음에도 불구하고 해당 보고서는 구성기를 통해 생성되어야 합니다.
액세스 제어 시스템에 대한 외부 보고서를 생성하는 예를 살펴보겠습니다.

이제 1C로 이동하여 보고서를 열어 취해진 조치가 올바른지 확인합니다. 모든 데이터가 반영되며, 그룹화는 축소 및 확장이 가능합니다. 보시다시피 액세스 제어 시스템을 사용하면 비표준 요구 사항을 제외하고 코드를 작성하지 않고도 본격적인 보고서를 받을 수 있습니다. 대부분의 보고서가 비슷한 구조를 가지고 있다는 점을 고려하면 액세스 제어 시스템에 대한 지식이 있으면 이러한 개체를 개발하는 데 소요되는 시간이 크게 단축됩니다.
이 메커니즘은 광범위한 보고 기능을 지원하므로 매우 널리 사용됩니다. 또한 개발자뿐만 아니라 일반 사용자도 사용할 수 있습니다.
ACS 기능
우리가 신고를 했는데, 사용자가 와서 약간의 수정을 요청하는 상황이 있습니다. 예를 들어, 제품 이름 대신 품목 번호를 표시하십시오. SKD에서는 사용자가 "추가" - "옵션 변경..." 버튼을 사용하여 독립적으로 이러한 수정 작업을 수행할 수 있습니다.

열리는 창은 구성기 보고서의 설정 창과 유사하며 기능도 유사합니다. 작업을 해결하려면 사용자는 "필드" 탭으로 이동하여 "명명법" 필드를 변경해야 합니다. 이 편집 필드는 두 번 클릭하면 열리고 "선택..." 버튼이 활성화됩니다.

열리는 창에서는 "명명법" 필드에 표시될 값을 선택할 수 있습니다. 일부 필드에는 왼쪽에 더하기 기호가 있습니다. 개발자가 이러한 필드에 링크를 배치했기 때문에 세부 정보를 볼 수 있습니다. "명명법"을 열고 필요한 기사를 봅니다. 선택해서 선택하세요.

보고서 옵션 변경 창에는 데이터 작성 시스템의 유용한 기능이 많이 포함되어 있습니다. 예를 들어, 사용자는 독립적으로 그룹화 순서를 변경하거나 선택 항목을 추가하거나 조건부 디자인을 적용할 수 있습니다. 편집을 완료하고 보고서를 생성합니다. 보시다시피 이제 전체 제품군이 기사 형식으로 표시됩니다.

SKD 1C:Enterprise 8.3 메커니즘은 개발자를 위한 확장된 기능도 제공합니다. 보고서를 개발할 때 "데이터 세트"와 "설정"이라는 2개의 탭만 사용했지만 ACS에는 더 많은 탭이 있습니다. 데이터 구성 시스템의 모든 기능을 사용하려면 각 탭의 용도를 이해해야 합니다.
- 데이터 세트 – 보고서 생성과 관련된 모든 쿼리가 여기에 나열됩니다.
- 데이터 세트 연결 – 첫 번째 탭에서 서로 다른 쿼리 간의 연결을 구축하는 데 사용됩니다.
- 계산된 필드 – 쿼리에서 생성되지 않은 추가된 필드 목록입니다. 여러 필드의 값을 기반으로 요청에서 1개의 값을 가져와야 하는 경우에 가장 자주 사용됩니다.
- 자원. 1C에서는 결과를 알아야 하는 필드의 이름입니다. 리소스는 합계, 수량, 최대값 등 다양한 산술 연산을 지원합니다.
- 옵션. 보고서를 생성하기 위해 사용자가 특정 데이터(예: 날짜, 부서 또는 명명법)를 입력해야 하는 경우에 사용됩니다.
- 레이아웃. 사용자가 고유하게 디자인된 보고서를 보고 싶어하는 경우를 위해 설계되었습니다. 서명을 위한 별도의 장소나 보고서의 새로운 상단 부분을 만들 수 있습니다. 이 모든 작업은 여기에서 수행할 수 있습니다.
- 중첩된 다이어그램. 보고서에 다른 보고서의 데이터가 포함되어야 하는 경우 필요합니다.
- 설정. 이 섹션에서는 표시할 필드를 선언하고, 그룹화하고, 보고서의 모양을 구성합니다.

개발자가 ACS 메커니즘에 통합한 가능성은 많지만 그 중 상당수는 극히 드물게 사용됩니다. 숙련된 1C 프로그래머라도 수년간 작업한 후에는 일부 기능을 사용하지 못할 수 있습니다. 출입 통제 시스템 작업을 성공적으로 시작하려면 기본 개념과 자주 사용되는 설정을 아는 것만으로도 충분합니다. 드문 경우지만 문서가 도움이 될 것입니다.
학생으로 사이트에 로그인하세요
학교 자료에 접근하려면 학생으로 로그인하세요.
초보자를 위한 데이터 구성 시스템 1C 8.3: 결과 계산(리소스)
이 강의의 목적은 다음과 같습니다:
- 제품 목록(음식 디렉토리), 칼로리 함량 및 맛을 표시하는 보고서를 작성하세요.
- 색상별로 제품을 그룹화합니다.
- 요약(리소스) 및 계산된 필드에 대해 알아보세요.
새 보고서 만들기
이전 강의와 마찬가지로 데이터베이스를 엽니다. 델리"구성기에서 메뉴를 통해 새 보고서를 생성합니다" 파일"->"새로운...":
문서 유형 - 외부 보고:

보고서 설정 양식에 이름을 " 제3과" 그리고 버튼을 누르세요 " 오픈데이터 구성도":

기본 스키마 이름을 그대로 두고 " 버튼을 클릭하세요. 준비가 된":

생성자를 통해 요청 추가
탭에서 " 데이터 세트" 클릭 녹색더하기 기호를 선택하고 " 데이터 세트 추가 - 쿼리":

요청 텍스트를 수동으로 작성하는 대신 다시 실행합니다. 쿼리 생성자:

"탭"에서 테이블"테이블을 드래그해" 음식" 첫 번째 열부터 두 번째 열까지:

표에서 선택 " 음식"요청할 필드입니다. 이렇게 하려면 해당 필드를 끌어서 놓습니다." 이름", "맛", "색상" 그리고 " 칼로리 함량" 두 번째 열부터 세 번째 열까지:

결과는 다음과 같습니다.

버튼을 누르세요 " 좋아요" - 요청 텍스트가 자동으로 생성되었습니다.

보고서 프리젠테이션 설정 생성
탭으로 이동 " 설정"를 클릭하고 마법의 지팡이, 전화하다 설정 디자이너:

보고서 유형 선택 " 목록..." 버튼을 누르고 " 더 나아가":

목록에 표시될 필드를 왼쪽 열에서 오른쪽으로 끌어서 "를 클릭합니다. 더 나아가":

왼쪽 열에서 오른쪽 필드로 드래그하세요. 색상" - 일어날거야 그룹화보고서의 줄. "를 클릭하세요. 좋아요":

그리고 여기에 디자이너의 작업 결과가 있습니다. 보고서의 계층 구조:
- 보고서는 전체적으로
- "색상" 그룹화
- 세부 항목 - 음식 이름이 있는 줄

보고서 저장(버튼 디스켓) 그리고 닫지 않고사용자 모드에서 구성 프로그램을 즉시 엽니다. 결과는 다음과 같습니다.

열 순서 변경
하지만 하자 순서를 바꾸자열(위쪽 및 아래쪽 화살표)을 아래 그림과 같이 만듭니다.

보고서를 저장하고 사용자 모드에서 다시 열어 보겠습니다.

좋아요, 그게 훨씬 낫네요.
칼로리 내용을 요약 해 봅시다
그룹별로 음식의 칼로리 함량을 요약해 보면 좋을 것 같습니다. 흰색 또는 노란색과 같은 모든 제품의 칼로리 함량 합계를 확인합니다. 또는 데이터베이스에 있는 모든 제품의 총 칼로리 함량을 알아보세요.
이를 위해 리소스를 계산하는 메커니즘이 있습니다.
탭으로 이동 " 자원"그리고 필드를 드래그하세요" 칼로리 함량"(요약해보겠습니다) 왼쪽부터 오른쪽으로.
이 경우 필드의 드롭다운 목록에서 표현식을 선택합니다. 양(칼로리)", 총계는 총계에 포함된 모든 요소의 합계가 되기 때문입니다.

보고서를 저장하고 생성합니다.

이제 각 그룹과 보고서 전체에 대한 결과가 표시됩니다.
칼로리 측면에서 (평균) 요약하자면
이제 다른 열에 나타나도록 합시다. 평균그룹별 및 보고서 전체의 제품 칼로리 함량.
기존 "칼로리" 열은 터치할 수 없습니다. 총계가 이미 표시되어 있으므로 다른 필드를 만들어 보겠습니다, 이는 "칼로리" 필드의 정확한 복사본이 됩니다.
이러한 "가상" 필드를 생성하려면 다음 메커니즘을 사용합니다. 계산된 필드.
탭으로 이동 " 계산된 필드"하고 누르세요. 녹색더하기 기호:

칼럼에서 " 데이터 경로"새 필드의 이름을 씁니다( 원활하게, 공백 없이). "라고 부르자 평균 칼로리 함량", 그리고 열에서 " 표현"새 필드가 계산될 기준으로 기존 필드의 이름을 씁니다. 거기에 씁니다. " 칼로리 함량". 열 " 표제"가 자동으로 채워집니다.

새 필드(" 평균 칼로리 함량"), 그러나 보고서 자체에는 표시되지 않습니다. 다시 전화해야 합니다. 설정 디자이너("마술 지팡이") 또는 이 필드를 추가하세요 수동으로.
해보자 두번째방법. 이렇게하려면 "탭으로 이동하십시오. 설정", 선택하다 " 보고서"(결국 보고서에 필드 전체를 추가하고 싶습니다.) 하단의 탭을 선택하세요." 선택된 필드"그리고 필드를 드래그하세요" 평균 칼로리 함량"왼쪽 열에서 오른쪽으로:

결과는 다음과 같습니다.

보고서를 저장하고 생성합니다.

필드가 나타나고 그 값이 "칼로리" 필드의 값임을 알 수 있습니다. 엄청난!
이를 위해 우리는 이미 우리에게 친숙한 메커니즘을 다시 사용할 것입니다. 자원(요약). 탭으로 이동 " 자원"그리고 필드를 드래그하세요" 평균 칼로리 함량"왼쪽 열에서 오른쪽으로:

게다가 "란에는 표현"선택하다" 평균(평균칼로리)":

보고서를 저장하고 생성합니다.

그룹, 즉 각 색상과 보고서 전체에 대해 평균값이 절대적으로 정확하게 계산되었음을 알 수 있습니다. 하지만 그들은 존재한다 추가 항목보고서에서 제거하려는 개별 제품(그룹 아님)
왜 등장했는지 아시나요(그룹별 값 아님)? 왜냐하면 우리가 필드를 추가했을 때 " 평균 칼로리 함량"보고서 설정의 두 번째 단계에서 우리는 보고서 전체이 새로운 필드는 " 요소에 추가되었습니다. 상세한 기록".
오류를 수정해 보겠습니다. 이렇게 하려면 " 탭으로 돌아가세요. 설정", 선택하다 " 세부 항목" 먼저 위에서(2단계) 다음으로 " 세부 항목"아래(3단계)에서 북마크로 이동" 선택된 필드" 오른쪽 열에 " 요소가 표시됩니다. 자동".
요소 " 자동" - 이것은 하나의 필드가 아닙니다. 이는 상위 수준 설정에 따라 자동으로 여기에 포함되는 여러 필드입니다.
이러한 필드가 무엇인지 보려면 " 요소를 클릭하세요. 자동" 오른쪽버튼을 누르고 " 확장하다":

요소 " 자동"는 다음 필드로 확장되었습니다.

그리고 여기가 우리 분야야" 평균 칼로리 함량"그 지점에서 여기로 왔어요" 보고서" 우리가 그를 거기로 끌고 갔을 때. 그냥 제거하자해당 출력을 제거하려면 이 필드 옆에 있는 상자를 선택하십시오.
우리는 접근 통제 시스템을 기반으로 구현된 보고서 설정을 좀 더 자세히 조사했습니다. 이제 보고서 옵션에 대한 보다 미묘하고 자세한 설정을 살펴보겠습니다. 보고서 옵션의 "고급" 설정 창은 "추가" - "기타" - "보고서 옵션 변경" 명령으로 호출됩니다.
보고서 버전 변경 창은 두 부분으로 구분됩니다.
1. 보고서 구조.
2. 보고서 설정.

보고서 옵션 구조 섹션은 표준 보고서 설정의 "구조" 탭과 유사합니다. 그룹화의 목적과 구성은 기사의 1부에서 자세히 설명합니다.
보고서 변형 구조 테이블에는 그룹화가 포함된 실제 열 외에도 다음과 같은 몇 가지 추가 열이 포함되어 있습니다.
보고서 옵션 설정 섹션에서는 사용자에게 필요에 맞게 보고서를 구성할 수 있는 충분한 기회를 제공합니다. 이는 1부에서 설명한 표준 보고서 설정과 거의 완전히 일치합니다. 섹션의 모든 탭을 살펴보고 차이점을 살펴보겠습니다.
설정 섹션은 다음 탭으로 구성됩니다.
1. 매개변수.사용자가 사용할 수 있는 ACS 매개변수가 포함되어 있습니다.
SKD 매개변수는 보고서 데이터를 얻기 위해 사용되는 값입니다. 이는 데이터를 선택하거나 확인하기 위한 조건값일 수도 있고, 보조값일 수도 있습니다.
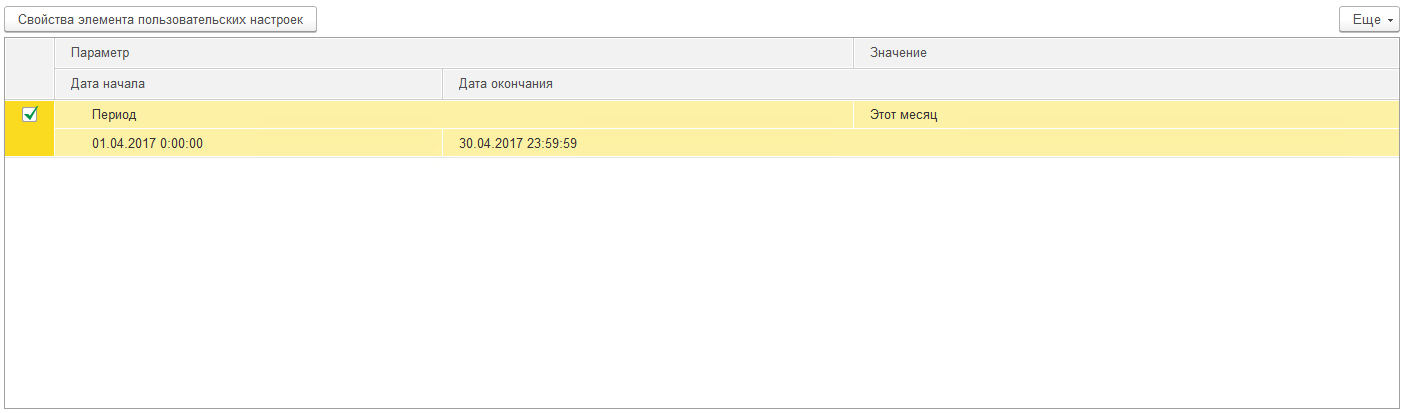
매개변수 테이블은 "매개변수" - "값" 형식으로 표시됩니다. 필요한 경우 매개변수 값을 변경할 수 있습니다. "사용자 정의 설정 요소 속성" 버튼을 클릭하면 요소의 사용자 정의 설정이 열립니다.

이 창에서 요소를 사용자 설정에 포함할지(즉, 보고서를 설정할 때 사용자에게 표시) 여부를 선택하고, 요소의 표시 및 편집 모드(보고서 헤더에서 빠른 액세스, 일반에서는 일반)를 설정할 수 있습니다. 보고서 설정 및 액세스할 수 없음).
사용자 정의 설정 항목 속성에는 그룹화 가능한 필드, 여백, 선택 항목 및 조건부 모양 요소도 있습니다.
2. 사용자 정의 필드.보고서에서 선택한 데이터를 기반으로 사용자가 직접 생성한 필드가 포함되어 있습니다.

사용자는 두 가지 유형의 필드를 추가할 수 있습니다.
- 새로운 선택 필드...
- 새로운 표현 필드...
선택 필드를 사용하면 주어진 조건에 따라 값을 계산할 수 있습니다. 선택 필드 편집 창에는 필드 제목과 필드의 선택, 값 및 표시가 지정된 테이블이 포함되어 있습니다. 선택은 원하는 값이 대체되는 조건입니다.

예를 들어 판매량 추정치를 계산해 보겠습니다. 제품이 10개 미만으로 팔리면 조금 팔린 것이고, 10개 이상이면 많이 팔린 것으로 가정하겠습니다. 이를 위해 계산된 필드에 대해 2개의 값을 설정합니다. 첫 번째는 "10"보다 작거나 같은 상품 수"를 선택하고, 두 번째는 "10보다 큼 상품 수"를 선택합니다. "".
표현식 필드를 사용하면 임의의 알고리즘을 사용하여 값을 계산할 수 있습니다. 쿼리 언어 및 내장 1C 프로그래밍 언어의 기능을 사용할 수 있습니다. 표현 필드 편집 창에는 세부 기록과 요약 기록 표현을 위한 두 개의 필드가 있습니다. 총 기록은 "보고서 구조" 영역에 구성된 그룹화입니다. 집계 기능("합계", "최소값", "최대값", "수량")을 사용해야 합니다.

예를 들어 평균 할인율을 계산해 보겠습니다. 평균 할인율은 [할인 없는 매출액] - [할인된 매출액] / [할인 없는 매출액]의 공식을 사용하여 계산됩니다. 할인을 적용하지 않은 판매량은 0이 될 수 있다는 점을 기억해두시고 SELECT 연산자를 이용해서 확인해보겠습니다. 우리는 다음과 같은 표현을 얻습니다.
· 자세한 항목은 다음을 참조하세요.
선택
[할인 없는 판매금액] = 0인 경우
그러면 0
그렇지 않은 경우 [할인 없는 판매 금액] - [할인 적용된 판매 금액] / [할인 없는 판매 금액]
끝
· 요약 레코드의 경우:
선택
Amount([할인 없는 판매금액]) = 0인 경우
그러면 0
그렇지 않으면 Sum([할인 없는 매출]) - Sum([할인 없는 매출]) / Sum([할인 없는 매출])
끝
앞에서 언급했듯이 총 기록 표현에서는 집계 함수 "Sum"을 사용합니다.
3. 그룹화 가능한 필드.보고서 변형의 결과를 그룹화하는 필드가 포함되어 있습니다. 그룹화된 필드는 각 그룹화마다 별도로 구성되지만, 구조 트리에서 "보고서" 루트를 선택하면 보고서 옵션에 대한 일반 그룹화된 필드를 설정할 수 있습니다. 보고서 결과의 필드, 사용자 정의 필드를 추가하거나 자동 필드를 선택할 수 있습니다. 그러면 시스템이 해당 필드를 자동으로 선택합니다. 이 탭에서는 그룹화된 필드의 순서를 변경할 수도 있습니다.

4. 필드.보고서 변형의 결과로 출력될 필드를 포함합니다. 필드는 그룹별로 별도로 구성되지만, 구조 트리에서 루트 "보고서"를 선택하면 보고서 옵션에 대한 공통 필드를 설정할 수 있습니다. 보고서 결과의 필드, 사용자 정의 필드를 추가하거나 자동 필드를 선택할 수 있습니다. 그러면 시스템이 해당 필드를 자동으로 선택합니다. 이 탭에서는 필드 순서를 변경할 수도 있습니다.
필드를 그룹화하여 보고서의 특정 부분을 논리적으로 강조 표시하거나 특별한 열 배열을 지정할 수 있습니다. 그룹을 추가하면 "위치" 열이 활성화되고 다음 위치 옵션 중 하나를 선택할 수 있습니다.
- 자동 - 시스템이 자동으로 필드를 배치합니다.
- 수평 - 필드가 수평으로 배치됩니다.
- 수직 - 필드가 수직으로 정렬됩니다.
- 별도의 열 - 필드는 다른 열에 있습니다.
- 함께 - 필드가 하나의 열에 위치합니다.

5. 선택.보고서 변형에 사용된 선택 사항이 포함되어 있습니다. 선택 항목 설정은 이 문서의 1부에서 자세히 설명했습니다. 필터는 그룹별로 별도로 구성되지만, 구조 트리에서 루트 "보고서"를 선택하면 보고서 옵션에 대한 일반 필터를 설정할 수 있습니다.

6. 정렬.보고서 변형에 사용되는 정렬 필드가 포함되어 있습니다. 정렬 필드 설정은 이 문서의 1부에서 자세히 설명했습니다. 정렬은 각 그룹화에 대해 별도로 구성되지만 구조 트리에서 루트 "보고서"를 선택하면 보고서 옵션에 대한 일반 정렬 필드를 설정할 수 있습니다.

7. 조건부 등록.보고서 변형에 사용되는 조건부 디자인 요소가 포함되어 있습니다. 조건부 표시 설정은 이 문서의 1부에서 자세히 설명했습니다. 조건부 표시는 각 그룹별로 별도로 구성되지만, 구조 트리에서 루트 "보고서"를 선택하면 보고서 옵션에 대한 조건부 표시의 일반 요소를 설정할 수 있습니다.

8. 추가 설정.추가 보고서 디자인 설정이 포함되어 있습니다. 보고서의 일반 모양, 필드 위치, 그룹화, 세부 정보, 리소스, 합계를 선택하고, 차트 설정을 지정하고, 제목, 매개변수 및 선택 표시를 제어하고, 리소스 위치를 결정하고, 헤더 및 그룹화를 수정할 수 있습니다. 보고서 버전의 열입니다.

결론적으로, 보고서 설정은 보고서 옵션으로 저장할 수 있을 뿐만 아니라 파일로 업로드할 수도 있습니다(메뉴 "추가" - "설정 저장"). 다운로드하려면 "설정 로드"를 선택하고 저장된 파일을 선택해야 합니다. 따라서 동일한 구성을 가진 여러 데이터베이스 간에 보고서 변형 설정을 전송할 수 있습니다.

이를 바탕으로 사용자는 자신의 필요에 맞게 보고서를 독립적으로 사용자 정의할 수 있을 뿐만 아니라 설정을 저장하고 필요할 경우 나중에 사용할 수도 있다는 점을 요약할 수 있습니다.
데이터 구성 시스템 표현 언어
데이터 구성 시스템 표현 언어는 시스템의 다양한 부분에서 사용되는 표현을 작성하도록 설계되었습니다.
표현식은 다음 하위 시스템에서 사용됩니다.
- 데이터 레이아웃 다이어그램 - 계산된 필드, 전체 필드, 연결 표현식 등을 설명합니다.
- 데이터 레이아웃 설정 - 사용자 정의 필드 표현식을 설명합니다.
- 데이터 레이아웃 레이아웃 - 데이터 세트 연결을 위한 표현식 설명, 레이아웃 매개변수 설명 등을 위한 것입니다.
리터럴
표현식에는 리터럴이 포함될 수 있습니다. 다음 유형의 리터럴이 가능합니다.
- 선;
- 숫자;
- 날짜;
- 부울.
선
문자열 리터럴은 "" 문자로 작성됩니다. 예를 들면 다음과 같습니다.
“문자열 리터럴”
문자열 리터럴 내에 "" 문자를 사용해야 하는 경우 해당 문자 두 개를 사용해야 합니다.
예를 들어:
“리터럴 “”따옴표로 묶음”““
숫자
숫자는 공백 없이 십진수 형식으로 기록됩니다. 소수 부분은 "." 기호를 사용하여 구분됩니다. 예를 들어:
10.5 200
날짜
날짜 리터럴은 키 리터럴 DATETIME을 사용하여 작성됩니다. 이 키워드 뒤에는 연도, 월, 일, 시, 분, 초가 괄호 안에 쉼표로 구분되어 나열됩니다. 시간 지정은 필요하지 않습니다.
예를 들어:
DATETIME(1975, 1, 06) – 1975년 1월 6일 DATETIME(2006, 12, 2, 23, 56, 57) – 2006년 12월 2일, 23시 56분 57초, 23시 56분 57초
부울
부울 값은 True(True), False(False) 리터럴을 사용하여 작성할 수 있습니다.
의미
다른 유형의 리터럴(시스템 열거, 미리 정의된 데이터)을 지정하려면 Value 키워드를 사용하고 그 뒤에 리터럴 이름을 괄호 안에 넣습니다.
값(계정 유형. 활성)
숫자에 대한 연산
단항 –
이 작업은 숫자의 부호를 반대 기호로 변경하기 위한 것입니다. 예를 들어:
판매량.수량
단항 +
이 작업은 번호에 대해 어떤 작업도 수행하지 않습니다. 예를 들어:
판매량.수량
바이너리 -
이 연산은 두 숫자의 차이를 계산하기 위한 것입니다. 예를 들어:
RemainingsAndTurnovers.InitialRemaining – RemainingsAndTurnovers.FinalRemainingsRemainingsAndTurnovers.InitialRemaining - 100 400 – 357
바이너리 +
이 연산은 두 숫자의 합을 계산하도록 설계되었습니다. 예를 들어:
RemainingsAndTurnover.InitialRemaining + RemainingAndTurnover.Turnover ResiduesAndTurnover.InitialRemaining + 100 400 + 357
일하다
이 연산은 두 숫자의 곱을 계산하도록 설계되었습니다. 예를 들어:
명칭. 가격 * 1.2 2 * 3.14
분할
이 연산은 한 피연산자를 다른 피연산자로 나눈 결과를 얻도록 설계되었습니다. 예를 들어:
명칭.가격 / 1.2 2 / 3.14
나머지 부문
이 연산은 한 피연산자를 다른 피연산자로 나눌 때 나머지를 얻도록 설계되었습니다. 예를 들어:
명칭 가격 % 1.2 2 % 3.14
문자열 연산
연결(바이너리 +)
이 작업은 두 문자열을 연결하도록 설계되었습니다. 예를 들어:
명명법.기사 + “:”+ 명명법.이름
좋다
이 작업은 문자열이 전달된 패턴과 일치하는지 확인합니다.
LIKE 연산자의 값은 다음과 같은 경우 TRUE입니다.<Выражения>패턴을 만족하고 그렇지 않으면 FALSE입니다.
다음 문자는<Строке_шаблона>줄의 다른 문자와는 다른 의미를 갖습니다.
- % - 백분율: 0개 이상의 임의 문자를 포함하는 시퀀스입니다.
- _ - 밑줄: 임의의 문자 하나;
- [...] - 대괄호 안의 하나 이상의 문자: 대괄호 안에 나열된 문자 중 하나. 열거형에는 범위가 포함될 수 있습니다. 예를 들어 a-z는 범위의 끝을 포함하여 범위에 포함된 임의의 문자를 의미합니다.
- [^...] - 대괄호 안의 부정 아이콘 뒤에 하나 이상의 문자가 옵니다. 부정 아이콘 뒤에 나열된 문자를 제외한 모든 문자.
다른 기호는 그 자체를 의미하며 추가 부하를 전달하지 않습니다. 나열된 문자 중 하나를 그대로 작성해야 하는 경우 앞에 다음 문자를 붙여야 합니다.<Спецсимвол>, SPECIAL CHARACTER 키워드(ESCAPE) 뒤에 지정됩니다.
예를 들어 템플릿
“%ABV[abvg]\_abv%” 특수 문자 “\”
일련의 문자로 구성된 부분 문자열을 의미합니다: 문자 A; 문자 B; 문자 B; 한 자리; 문자 a, b, c 또는 d 중 하나; 밑줄; 문자 a; 문자 b; 편지 v. 또한, 이 시퀀스는 라인의 임의의 위치에서 시작하여 위치할 수 있습니다.
비교 작업
같음
이 연산은 두 피연산자가 같은지 비교하기 위한 것입니다. 예를 들어:
Sales.Counterparty = Sales.NomenclatureMainSupplier
같지 않음
이 연산은 두 피연산자가 같지 않은지 비교하기 위한 것입니다. 예를 들어:
판매.상대방<>Sales.NomenclatureMainSupplier
더 적은
이 연산은 첫 번째 피연산자가 두 번째 피연산자보다 작은지 확인하도록 설계되었습니다. 예를 들어:
매출액현재.금액< ПродажиПрошлые.Сумма
더
이 연산은 첫 번째 피연산자가 두 번째 피연산자보다 큰지 확인하도록 설계되었습니다. 예를 들어:
SalesCurrent.Sum > SalesPast.Sum
작거나 같음
이 연산은 첫 번째 피연산자가 두 번째 피연산자보다 작거나 같은지 확인하도록 설계되었습니다. 예를 들어:
매출액현재.금액<= ПродажиПрошлые.Сумма
더 많거나 같음
이 연산은 첫 번째 피연산자가 두 번째 피연산자보다 크거나 같은지 확인하도록 설계되었습니다. 예를 들어:
SalesCurrent.Amount >= SalesPast.Amount
작전 B
이 작업은 전달된 값 목록에 값이 있는지 확인합니다. 작업 결과는 값이 발견되면 True이고, 그렇지 않으면 False입니다. 예를 들어:
품목 B(&제품1, &제품2)
데이터 세트에 값이 있는지 확인하는 작업
이 작업은 지정된 데이터 세트에 값이 있는지 확인합니다. 검증 데이터 세트에는 하나의 필드가 포함되어야 합니다. 예를 들어:
거래상대방에 대한 판매.
NULL 값을 확인하는 작업
이 작업은 값이 NULL인 경우 True를 반환합니다. 예를 들어:
판매.상대방이 NULL입니다.
NULL 부등식 값을 확인하는 작업
이 작업은 값이 NULL이 아닌 경우 True를 반환합니다. 예를 들어:
판매상대방은 NULL이 아닙니다.
논리 연산
논리 연산은 부울 유형의 표현식을 피연산자로 허용합니다.
작동하지 않음
NOT 연산은 피연산자가 False이면 True를 반환하고 피연산자가 True이면 False를 반환합니다. 예를 들어:
문서.수취인 아님 = 문서.위탁자
작전 I
AND 연산은 두 피연산자가 모두 True이면 True를 반환하고, 피연산자 중 하나가 False이면 False를 반환합니다. 예를 들어:
Document.Consignee = Document.Consignor AND Document.Consignee = &상대방
OR 연산
OR 연산은 피연산자 중 하나가 True이면 True를 반환하고, 두 피연산자가 모두 False이면 False를 반환합니다. 예를 들어:
Document.Consignee = Document.Consignor OR Document.Consignee = &상대방
집계 함수
집계 함수는 데이터 집합에 대해 일부 작업을 수행합니다.
합집합
Sum 집계 함수는 모든 세부 레코드에 대한 인수로 전달된 표현식 값의 합계를 계산합니다. 예를 들어:
금액(매출.금액회전율)
수량
Count 함수는 NULL이 아닌 값의 개수를 계산합니다. 예를 들어:
수량(판매.상대방)
다른 수
이 함수는 고유 값의 수를 계산합니다. 예를 들어:
수량(다양한 판매.상대방)
최고
함수는 최대값을 얻습니다. 예를 들어:
최대(남은.수량)
최저한의
이 함수는 최소값을 얻습니다. 예를 들어:
최소(남은.수량)
평균
이 함수는 NULL이 아닌 값의 평균을 가져옵니다. 예를 들어:
평균(남은.수량)
기타 작업
작업 선택
Select 작업은 특정 조건이 충족되면 여러 값 중 하나를 선택하는 작업입니다. 예를 들어:
금액 > 1000인 경우 선택하고 그렇지 않은 경우 금액 0 끝
두 값을 비교하는 규칙
비교되는 값의 유형이 서로 다른 경우 유형의 우선 순위에 따라 값 간의 관계가 결정됩니다.
- NULL(최저);
- 부울;
- 숫자;
- 날짜;
- 선;
- 참조 유형
다양한 참조 유형 간의 관계는 특정 유형에 해당하는 테이블의 참조 번호를 기반으로 결정됩니다.
데이터 유형이 동일한 경우 다음 규칙에 따라 값을 비교합니다.
- 부울 유형의 경우 TRUE 값은 FALSE 값보다 큽니다.
- Number 유형에는 숫자에 대한 일반적인 비교 규칙이 있습니다.
- 날짜 유형의 경우 이전 날짜는 이후 날짜보다 작습니다.
- 문자열 유형의 경우 - 데이터베이스의 확립된 국가 특성에 따른 문자열 비교
- 참조 유형은 해당 값(레코드 번호 등)을 기준으로 비교됩니다.
NULL 값 작업
피연산자 중 하나가 NULL인 모든 연산은 NULL 결과를 생성합니다.
예외가 있습니다:
- AND 연산은 피연산자 중 False가 아닌 경우에만 NULL을 반환합니다.
- OR 연산은 피연산자 중 어느 것도 True가 아닌 경우에만 NULL을 반환합니다.
운영 우선순위
작업의 우선순위는 다음과 같습니다(첫 번째 줄의 우선순위가 가장 낮습니다).
- B는 NULL이고, NULL이 아닙니다.
- =, <>, <=, <, >=, >;
- 바이너리 +, 바이너리 – ;
- *, /, %;
- 단항 +, 단항 -.
데이터 구성 시스템 표현 언어 기능
계산하다
계산 기능은 특정 그룹화의 맥락에서 표현식을 계산하도록 설계되었습니다. 이 함수에는 다음과 같은 매개변수가 있습니다.
- 표현. 문자열을 입력합니다. 계산된 표현식을 포함합니다.
- 그룹화. 문자열을 입력합니다. 표현식이 평가되는 컨텍스트의 그룹화 이름을 포함합니다. 빈 문자열을 그룹화 이름으로 사용하는 경우 현재 그룹화 컨텍스트에서 계산이 수행됩니다. GrandTotal 문자열이 그룹 이름으로 사용되는 경우 총합계 컨텍스트에서 계산이 수행됩니다. 그렇지 않으면 이름이 같은 상위 그룹의 컨텍스트에서 계산이 수행됩니다. 예를 들어:
이 예에서 결과는 전체 레이아웃의 동일한 필드 금액에 대한 그룹화 레코드의 "Sales.AmountTurnover" 필드 금액의 비율입니다.
수준
이 기능은 현재 녹음 레벨을 가져오도록 설계되었습니다.
수준()
번호순서
다음 시퀀스 번호를 가져옵니다.
번호별순서()
번호순서순서그룹화
현재 그룹의 다음 서수를 반환합니다.
NumberByOrderInGroup()
체재
전달된 값의 형식화된 문자열을 가져옵니다.
형식 문자열은 1C:Enterprise 형식 문자열에 따라 설정됩니다.
옵션:
- 의미;
- 형식 문자열.
형식(소모품 송장.Doc 금액, "NPV=2")
기간의 시작
옵션:
- 분;
- 낮;
- 일주일;
- 월;
- 4분의 1;
- 10년;
- 반년.
StartPeriod(DateTime(2002, 10, 12, 10, 15, 34), "월")
결과:
01.10.2002 0:00:00
기간 종료
이 함수는 주어진 날짜에서 특정 날짜를 추출하도록 설계되었습니다.
옵션:
- 날짜. 날짜를 입력하세요. 특정 날짜;
- 기간 유형. 문자열을 입력합니다. 다음 값 중 하나를 포함합니다.
- 분;
- 낮;
- 일주일;
- 월;
- 4분의 1;
- 10년;
- 반년.
EndPeriod(DateTime(2002, 10, 12, 10, 15, 34), "주")
결과:
13.10.2002 23:59:59
날짜 추가
이 기능은 날짜에 특정 값을 추가하도록 설계되었습니다.
옵션:
- 확대 유형. 문자열을 입력합니다. 다음 값 중 하나를 포함합니다.
- 분;
- 낮;
- 일주일;
- 월;
- 4분의 1;
- 10년;
- 반년.
- 금액 - 날짜를 늘려야 하는 금액입니다. 번호를 입력하세요. 소수 부분은 무시됩니다.
AddToDate(DateTime(2002, 10, 12, 10, 15, 34), "월", 1)
결과:
12.11.2002 10:15:34
차이 날짜
이 함수는 두 날짜의 차이를 얻도록 설계되었습니다.
옵션:
- 표현. 날짜를 입력하세요. 원래 날짜
- 표현. 날짜를 입력하세요. 차감된 날짜;
- 차이 유형. 문자열을 입력합니다. 다음 값 중 하나를 포함합니다.
- 두번째;
- 분;
- 낮;
- 월;
- 4분의 1;
DATEDIFFERENCE(DATETIME(2002, 10, 12, 10, 15, 34), DATETIME(2002, 10, 14, 9, 18, 06), "요일")
결과:
하위 문자열
이 함수는 문자열에서 부분 문자열을 추출하도록 설계되었습니다.
옵션:
- 선. 문자열을 입력합니다. 하위 문자열이 추출되는 문자열입니다.
- 위치. 번호를 입력하세요. 문자열에서 추출할 부분 문자열이 시작되는 문자의 위치입니다.
- 길이. 번호를 입력하세요. 할당된 하위 문자열의 길이입니다.
SUBSTRING(계정.주소, 1, 4)
줄 길이
이 함수는 문자열의 길이를 결정하도록 설계되었습니다.
매개변수:
- 선. 문자열을 입력합니다. 길이가 결정되는 문자열입니다.
라인(상대방.주소)
년도
이 함수는 Date 유형 값에서 연도를 추출하도록 설계되었습니다.
매개변수:
- 날짜. 날짜를 입력하세요. 연도가 결정되는 날짜입니다.
YEAR(비용.날짜)
4분의 1
이 함수는 날짜 유형 값에서 분기 번호를 추출하도록 설계되었습니다. 분기 번호의 범위는 일반적으로 1에서 4까지입니다.
매개변수
- 날짜. 날짜를 입력하세요. 분기가 결정되는 날짜
월
이 함수는 Date 유형 값에서 월 번호를 추출하도록 설계되었습니다. 월 번호의 범위는 일반적으로 1부터 12까지입니다.
- 날짜. 날짜를 입력하세요. 월이 결정되는 날짜입니다.
올해의 날
이 함수는 Date 유형 값에서 해당 연도의 날짜를 가져오도록 설계되었습니다. 연중 날짜의 범위는 일반적으로 1부터 365(366)까지입니다.
- 날짜. 날짜를 입력하세요. 해당 연도의 날짜가 결정되는 날짜입니다.
낮
이 함수는 Date 유형 값에서 해당 월의 일자를 가져오도록 설계되었습니다. 해당 월의 날짜 범위는 일반적으로 1부터 31까지입니다.
- 날짜. 날짜를 입력하세요. 해당 월의 날짜가 결정되는 날짜입니다.
일주일
이 함수는 날짜 유형 값에서 해당 연도의 주 수를 가져오도록 설계되었습니다. 한 해의 주는 1부터 시작하여 번호가 매겨집니다.
- 날짜. 날짜를 입력하세요. 주 번호가 결정되는 날짜입니다.
요일
이 함수는 Date 유형 값에서 요일을 가져오도록 설계되었습니다. 일반적인 요일은 1(월요일)부터 7(일요일)까지입니다.
- 날짜. 날짜를 입력하세요. 요일이 결정되는 날짜입니다.
시간
이 함수는 Date 유형 값에서 시간을 가져오도록 설계되었습니다. 하루의 시간 범위는 0부터 23까지입니다.
- 날짜. 날짜를 입력하세요. 하루의 시간이 결정되는 날짜입니다.
분
이 함수는 날짜 유형 값에서 시간의 분을 가져오도록 설계되었습니다. 분의 범위는 0부터 59까지입니다.
- 날짜. 날짜를 입력하세요. 분을 결정하는 날짜입니다.
두번째
이 함수는 날짜 유형 값에서 1분의 1초를 가져오도록 설계되었습니다. 분의 초 범위는 0부터 59까지입니다.
- 날짜. 날짜를 입력하세요. 분의 초가 결정되는 날짜입니다.
표현하다
이 함수는 복합 유형을 포함할 수 있는 표현식에서 유형을 추출하도록 설계되었습니다. 표현식에 필수 유형이 아닌 유형이 포함되어 있으면 NULL이 반환됩니다.
옵션:
- 변환할 표현식입니다.
- 유형 표시. 문자열을 입력합니다. 유형 문자열을 포함합니다. 예를 들어 "숫자", "문자열" 등이 있습니다. 기본 유형 외에도 이 줄에는 테이블 이름이 포함될 수 있습니다. 이 경우 지정된 테이블에 대한 참조를 표현하려고 시도합니다.
Express(Data.Props1, "번호(10,3)")
IsNull
이 함수는 첫 번째 매개변수의 값이 NULL인 경우 두 번째 매개변수의 값을 반환합니다.
그렇지 않으면 첫 번째 매개변수의 값이 반환됩니다.
YesNULL(Amount(Sales.AmountTurnover), 0)
공통 모듈의 기능
데이터 구성 엔진 표현식에는 전역 공통 구성 모듈의 기능에 대한 호출이 포함될 수 있습니다. 이러한 함수를 호출하는 데 추가 구문이 필요하지 않습니다.
이 예에서는 "AbbreviatedName" 함수가 일반 구성 모듈에서 호출됩니다.
공통 모듈 기능의 사용은 적절한 데이터 구성 프로세서 매개변수가 지정된 경우에만 허용됩니다.
또한 공통 모듈의 기능은 사용자 정의 필드 표현식에서 사용할 수 없습니다.
다음 내용을 읽어보는 것이 도움이 될 수 있습니다.
- 개인의 사회적 지위 노동 계급의 문제;
- 번호로 확성기 지점을 찾는 방법;
- 비트코인 교환으로 돈을 버는 방법: 본질, 단계별 지침 및 경고 거래소에서 수입을 얻는 본질;
- 쿼츠 시계는 어떻게 작동하나요?;
- Galaxy S8 및 S8 Plus의 습기 보호 - 기술의 장단점 충전 포트에서 습기가 감지되었습니다.;
- 데스크톱 프로그램을 다운로드하는 방법;
- Android에서 Google과 연락처를 동기화하는 방법 Xiaomi mi5 SIM 카드에서 연락처를 복사하는 방법;
- Samsung Galaxy A3 스마트폰 리뷰: 세련된 "중급";